CogGym
A scalable framework for comparing AI models against humans using cognitive science experiments
This page describes CogGym: Towards Large-Scale Comparative Evaluation of Human and Machine Cognition, a benchmark and infrastructure project developed in collaboration with over 30 research labs.
AI benchmarks typically measure accuracy against objective ground truth. But arriving at the correct answer is not the same as thinking like a human. CogGym asks a different question: across the broad space of cognitive science experiments developed over decades to characterize human thought, how well do AI models actually align with human cognition?
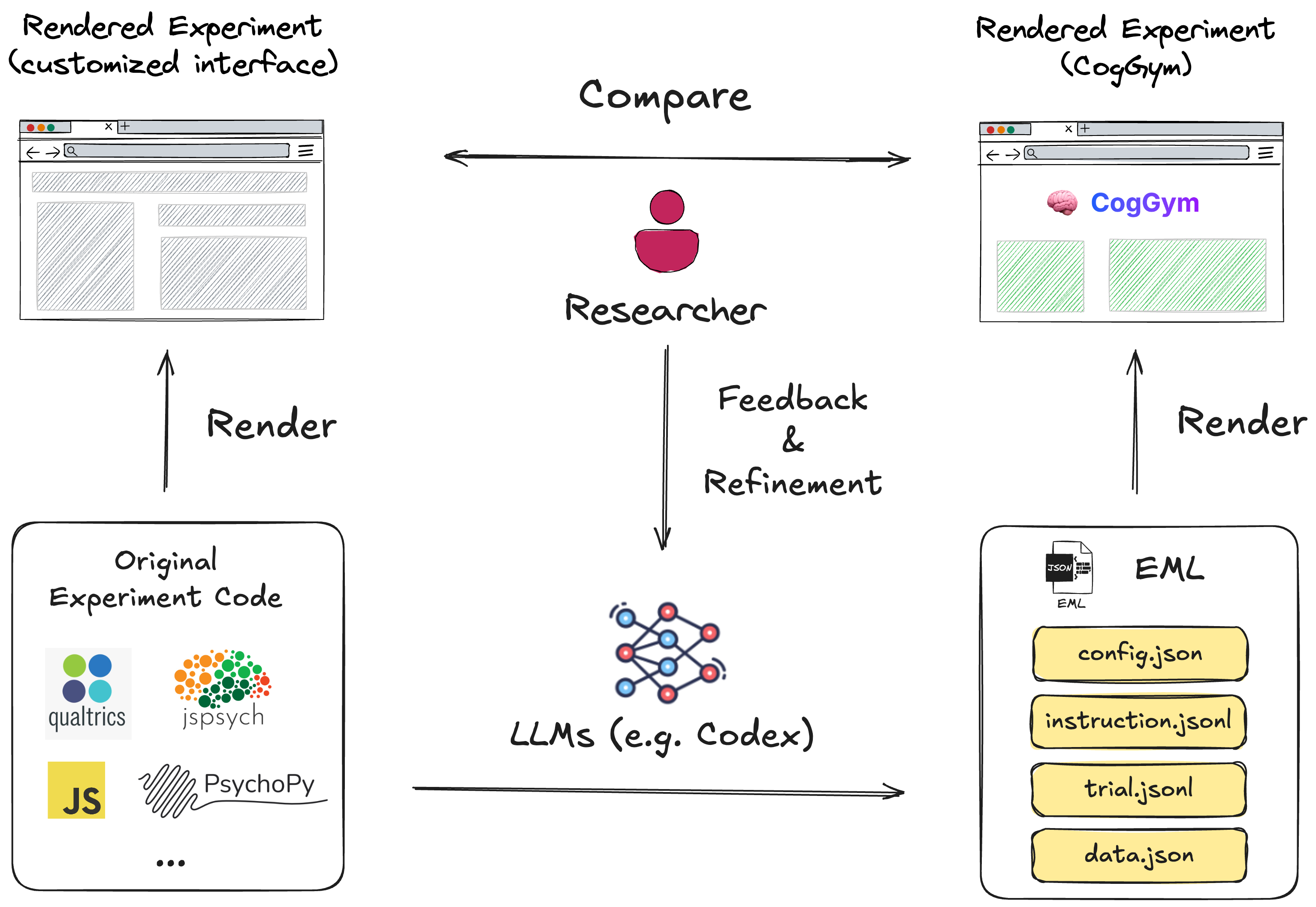
The core challenge is scale. Cognitive experiments are highly diverse in modality (text, audio, visual) and are built across heterogeneous software frameworks (PsychoPy, jsPsych, MATLAB). CogGym introduces the Experiment Markup Language (EML), a high-level, model-agnostic format that abstracts experimental logic — stimulus presentation, trial structure, response collection — into structured specifications. An expert-in-the-loop, LLM-assisted translation pipeline converts diverse paradigms into EML, enabling cognitive experiments to be administered to AI models at scale for the first time.
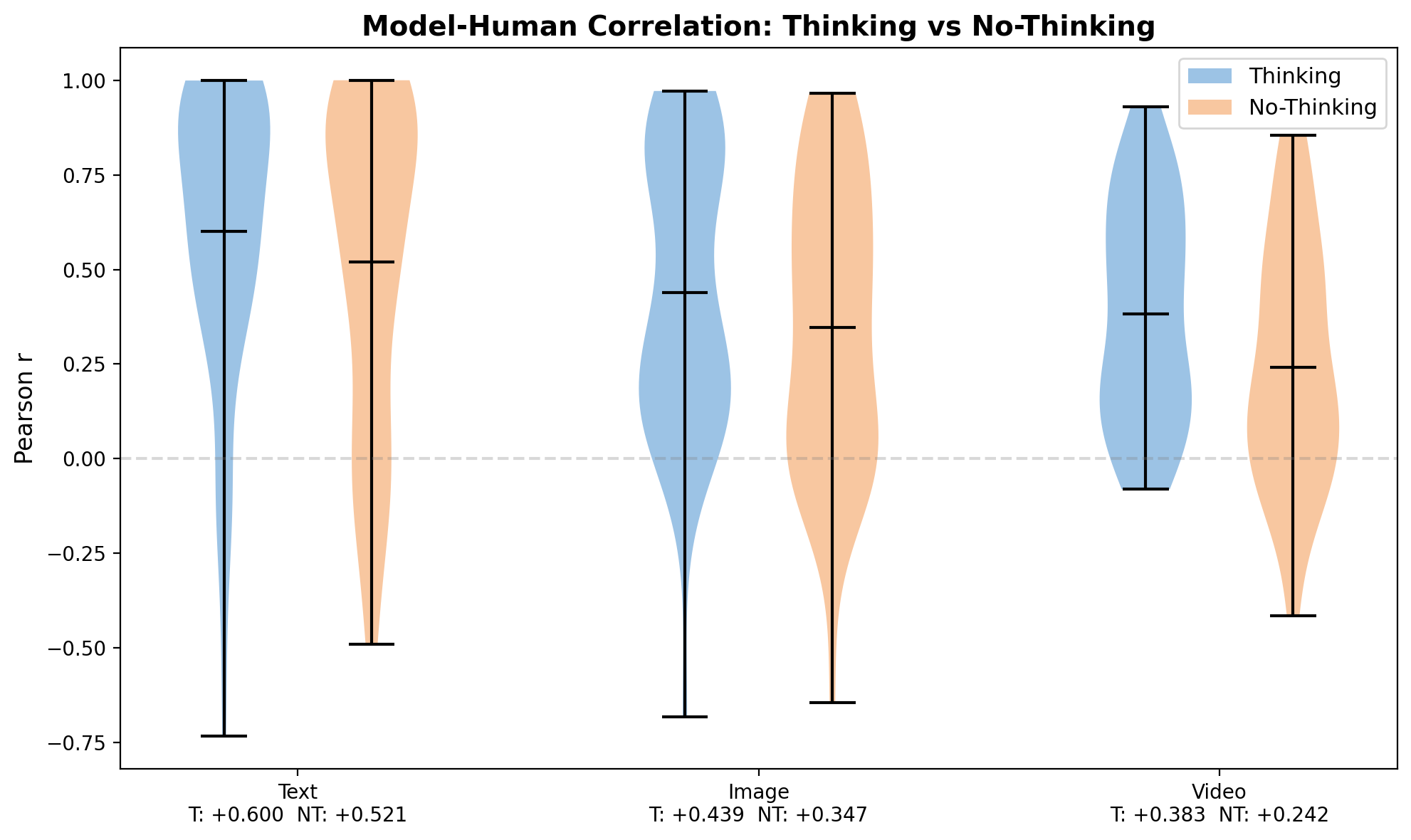
The current version focuses on rational common-sense reasoning: causal inference, decision-making under uncertainty, social cognition, moral judgment, and probabilistic thinking. Through partnerships with over 30 labs, we standardized 320 experiments from 100 published papers and evaluated 35 models released between April 2024 and April 2026 across text, image, and video modalities.
Three key findings:
-
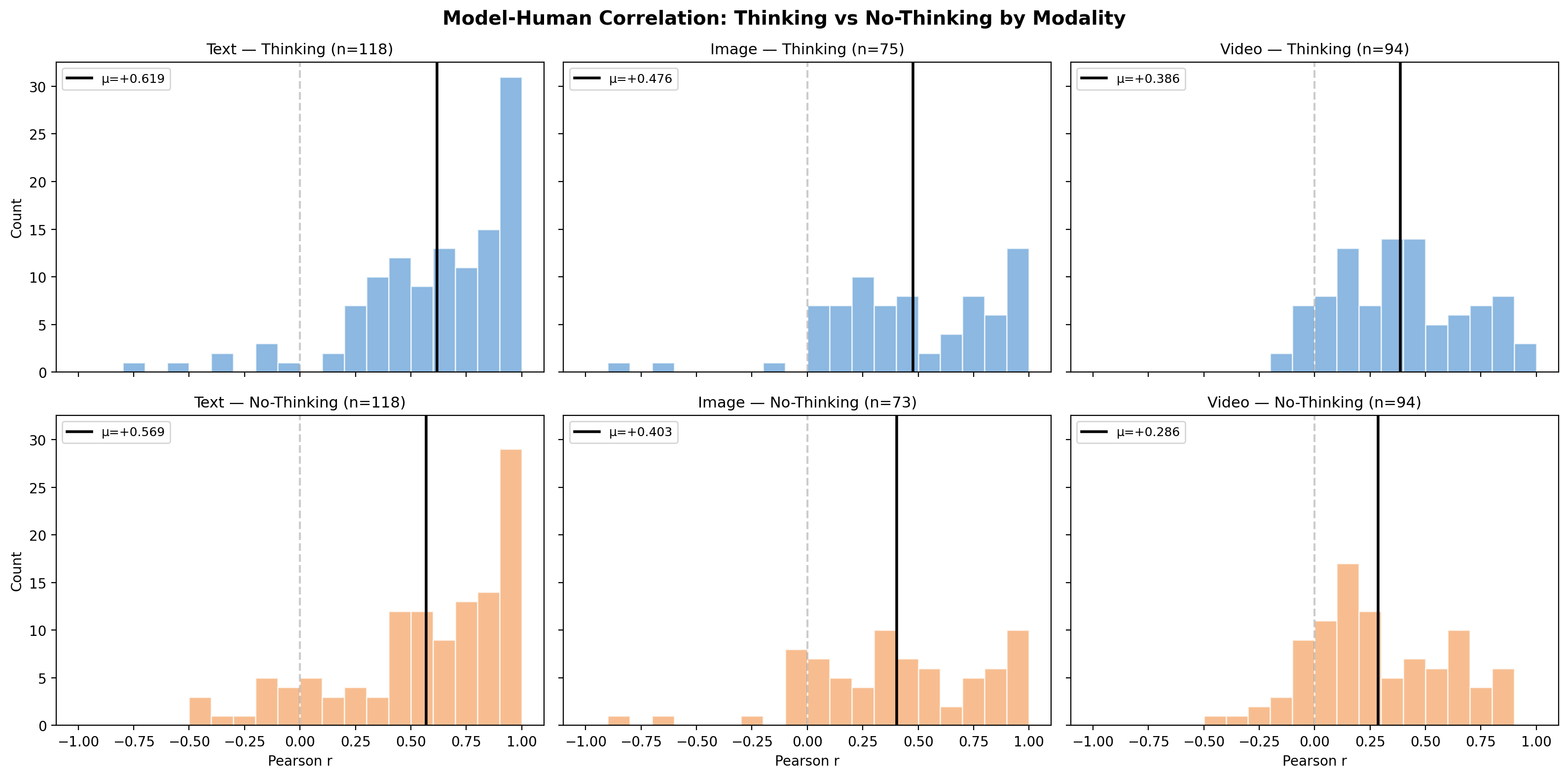
Progress in cognitive alignment has largely stagnated. Despite rapid gains in general capabilities, most models cluster in a narrow band (R² = 0.23–0.33) with human responses — far below human split-half reliability (R² = 0.85).
-
Models approximate the group mean but not the distribution. Models learn to mimic an “average human” without capturing individual heterogeneity. Divergence ratios remain flat at ~3× human variability.
-
Modality is a major bottleneck. Only 2.5% of text experiments are universally hard for all models, but 27.6% of video experiments have no model achieving r > 0.2, revealing that perceptual grounding remains a fundamental challenge.
CogGym is designed as a living evaluation framework — continuously incorporating new experiments and human replications as AI capabilities evolve. The goal is a persistent grand challenge: to develop computational models that truly think like humans.