What Matters in RL for Diffusion Models?
The dominant role of noise in RL post-training for diffusion models
This page describes What Matters in RL for Diffusion Models? The Dominant Role of Noise, submitted to NeurIPS 2026.
Reinforcement learning has become a powerful paradigm for post-training generative models — improving reasoning in language models and improving alignment in diffusion models. But a basic question has gone unanswered: what actually drives learning in RL-based diffusion training?
For language models, the signal is clear — it comes from the response. But diffusion models introduce a second axis of stochasticity: noise initialization. Each generated image is shaped both by the text prompt and by the noise sample that seeds the denoising trajectory. These two axes both produce variation in reward, but their relative contributions have never been disentangled — until now.
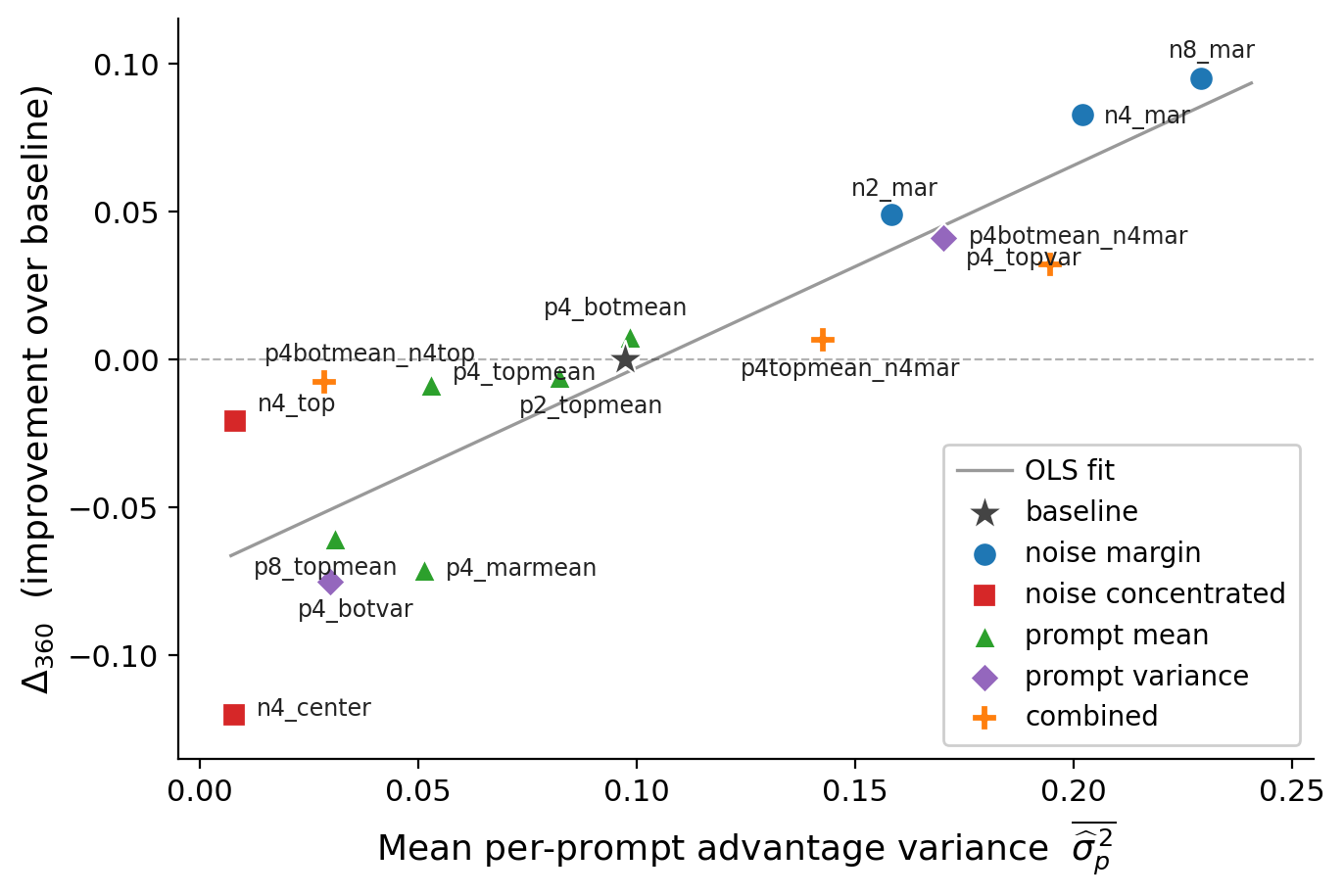
We present the first systematic study separating prompt-level and noise-level sources of optimization signal in RL training for diffusion models. The key finding: noise dominates. Reward variance and policy-gradient informativeness are driven overwhelmingly by differences among trajectories generated from the same prompt — not by differences across prompts. Prompt-level variation contributes substantially less after group-wise normalization.
This has a direct practical implication: if noise is what matters, training should be structured to maximize informative noise-induced variation. We introduce two strategies:
- Structured noise oversampling: generate more candidate trajectories per prompt, exploiting the noise axis more efficiently under the same compute budget.
- Margin-based trajectory selection: select training pairs with the largest reward margin, prioritizing trajectories that carry the most learning signal.
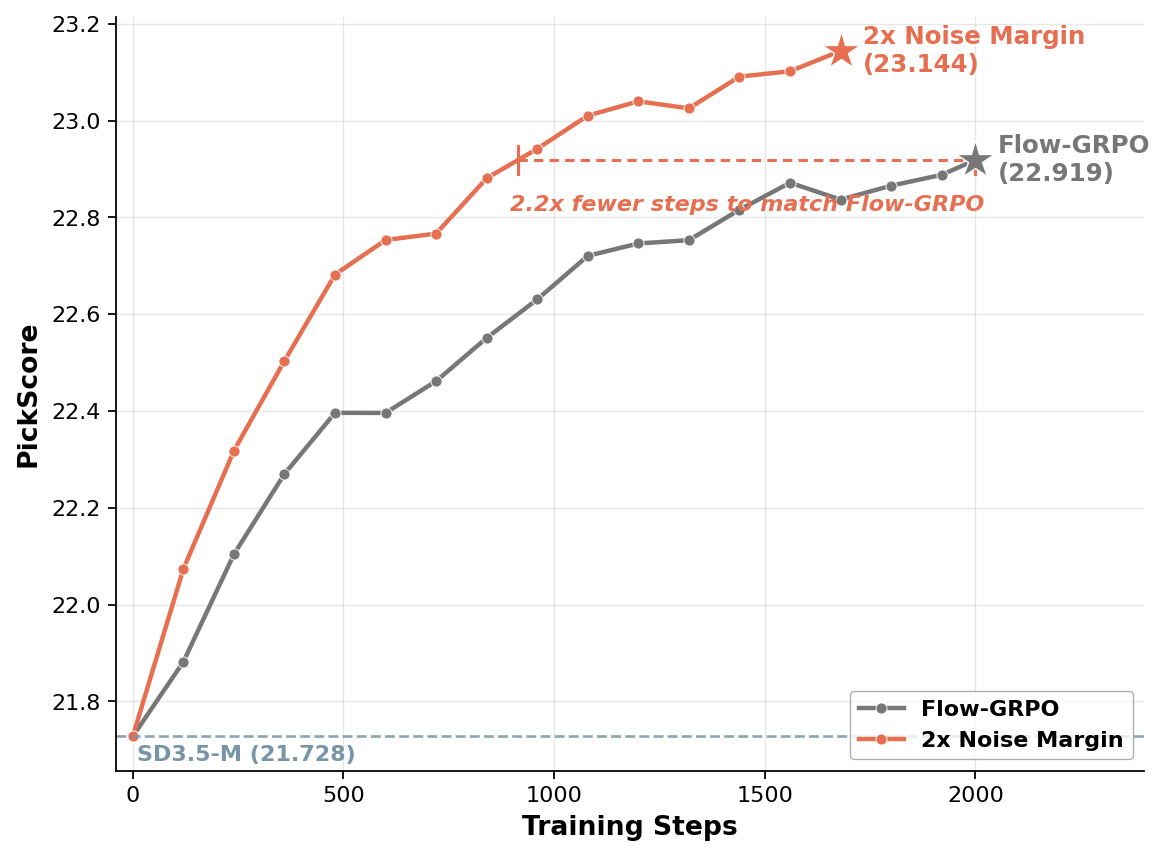
Both strategies plug directly into FlowGRPO, the standard RL framework for flow-based diffusion models. Across three tasks — compositional image generation, OCR-based text rendering, and human preference alignment — noise margin selection consistently improves over the baseline. The 2x Noise Margin variant reaches FlowGRPO’s final PickScore in 2.2× fewer training steps, and ends with a higher final score (23.14 vs. 22.92). Prompt-level filtering, by contrast, yields substantially weaker gains — confirming the asymmetry.


The broader takeaway is that RL for diffusion models is governed by trajectory-level exploration and selection over the noise-induced space — a fundamentally different structure from RL alignment in autoregressive language models, where the prompt is the primary axis of variation. Understanding this distinction matters for how we design data collection, sampling strategies, and reward-weighting schemes for the next generation of RL-trained generative models.