Rewarded Region Replay (R3)
Reinforcement Learning in Sparse Reward Environments
This project arises from the class Computational Sensorimotor Learning, where my teammates and I devised an algorithm that consistently outperforms the existing PPO and DDQN agents in sparse reward environments. We call our algorithm Rewarded Region Replay (R3). R3 improves sample efficiency by using a replay buffer which contains past successful trajectories with reward above a certain threshold, which are used to update a PPO agent with importance sampling. Crucially, we discard the importance sampling factors which are above a certain ratio to reduce variance and stabilize training. We found that R3 significantly outperforms PPO in Minigrid environments with sparse rewards and discrete action space, such as DoorKeyEnv and CrossingEnv, and moreover we found that the improvement margin of our method versus baseline PPO increases with the complexity of the environment. We also benchmarked the performance of R3 against DDQN (Double Deep Q-Network), which is a standard baseline in off-policy methods for discrete actions, and found that R3 also outperforms DDQN agent in DoorKeyEnv.
Below are the performance of R3 benchmarked against PPO and DDQN agents in DoorKeyEnv.
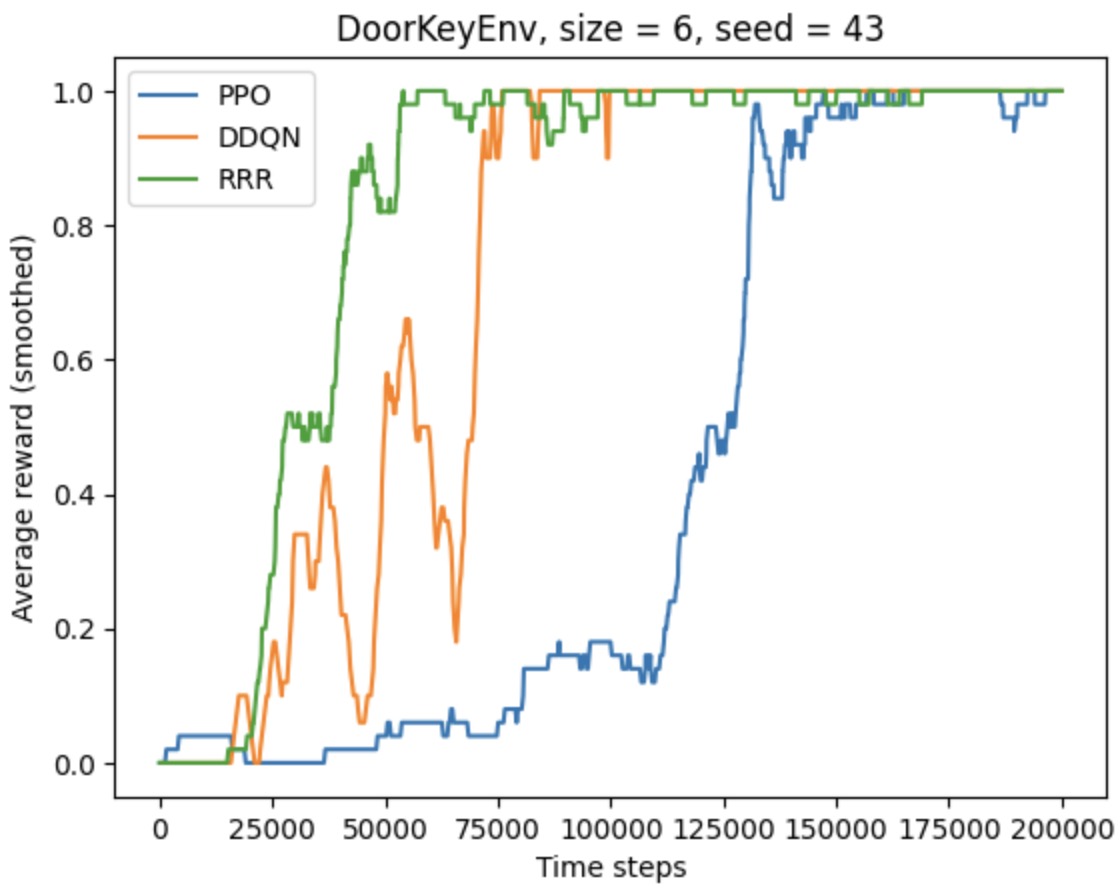
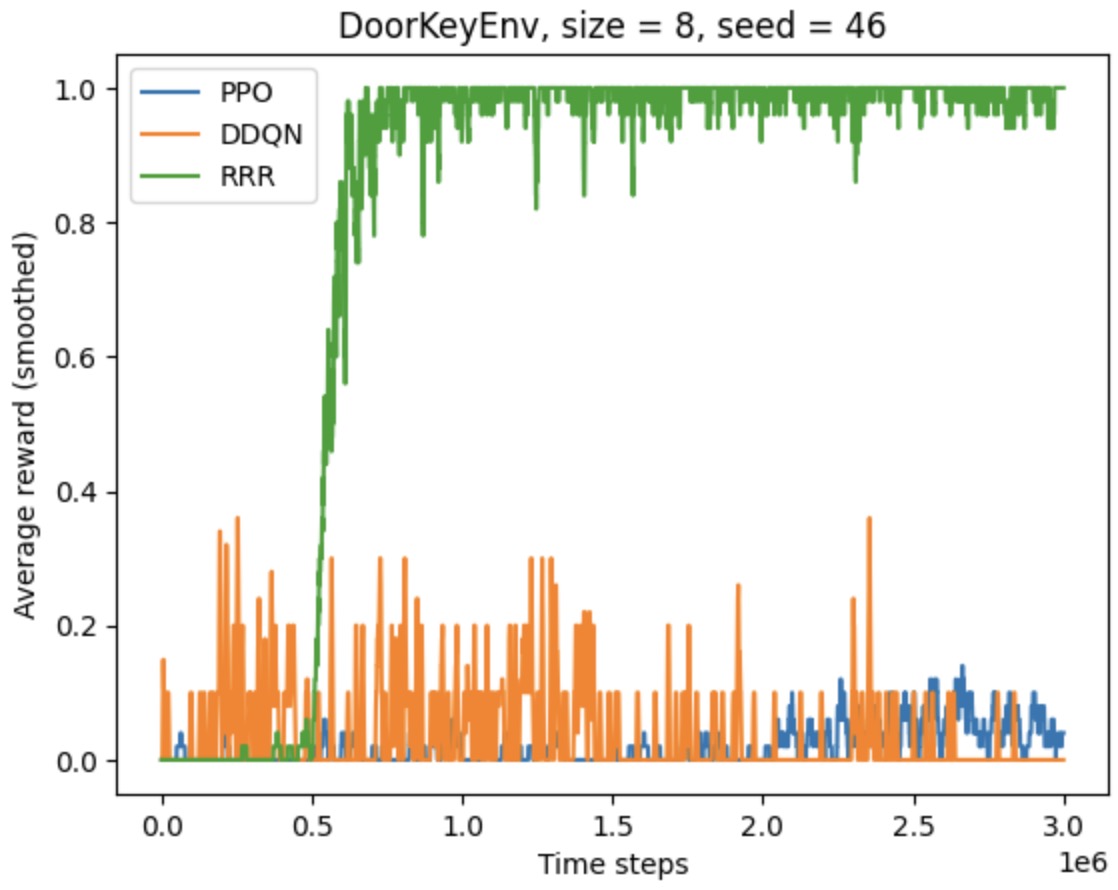
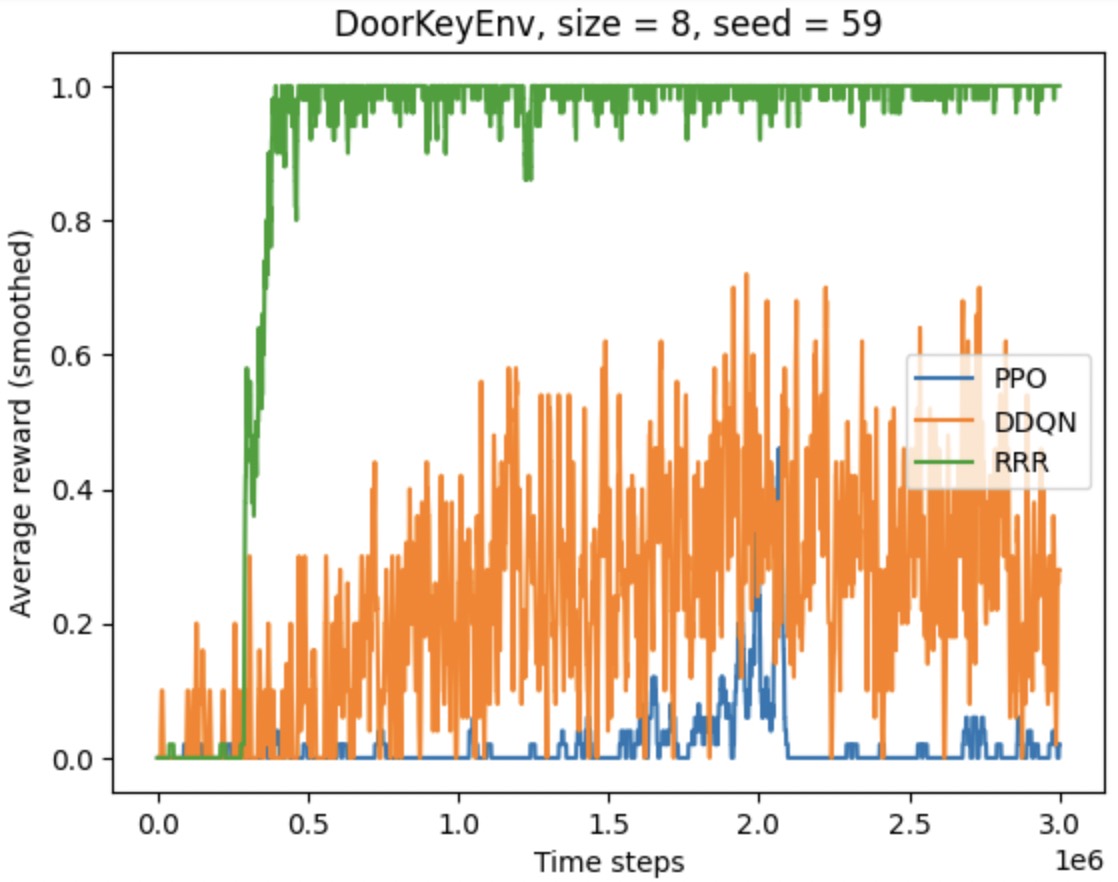
This work has been submitted to Neurips 2024 for review.
