KINA Benchmark
A high-density benchmark spanning 261 disciplines with game-theoretic annotation
This page describes KINA (Knowledge Index of Noah’s Ark), a benchmark for evaluating the disciplinary knowledge boundaries of frontier AI models, built at 2077AI.
Existing benchmarks for evaluating AI knowledge suffer from three structural problems: they prioritize scale or extreme difficulty over disciplinary representativeness, they are vulnerable to data contamination, and they rely on blind-trust annotations prone to “lazy consensus” — where annotators agree without independent reasoning. KINA addresses all three.
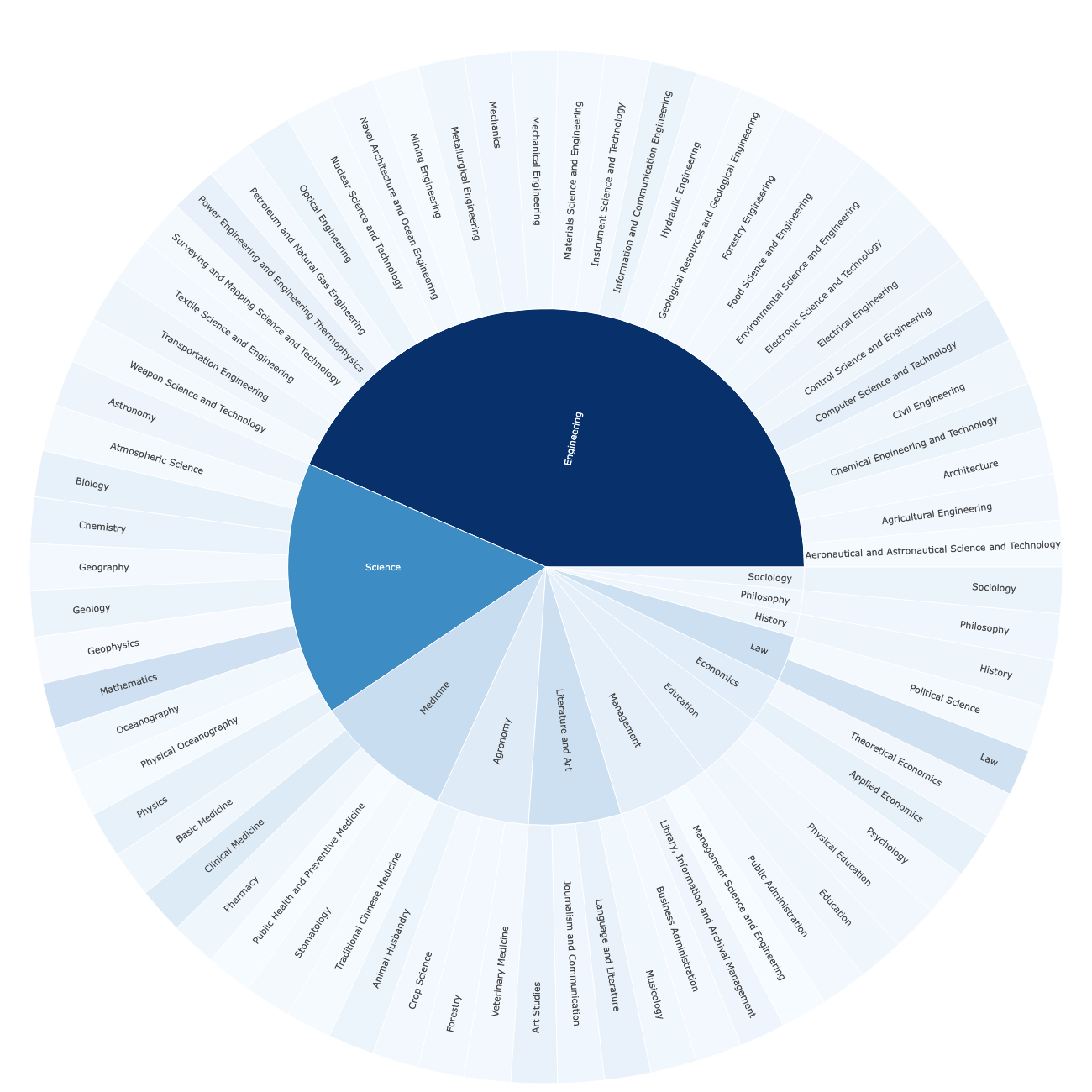
KINA spans 261 disciplines across the full breadth of human knowledge, organized into a three-level taxonomy. Each question uses a 10-option format to suppress guessing, with a strict difficulty threshold that filters out surface-level memorization. The result is a benchmark that rewards genuine reasoning over recall.
The annotation pipeline is designed around a Nash equilibrium incentive structure. Reviewer payoffs are structured so that honest, independent evaluation is the individually rational strategy, making collusion and lazy consensus irrational at equilibrium. This game-theoretic design is domain-agnostic and is released as a reusable framework alongside the dataset.
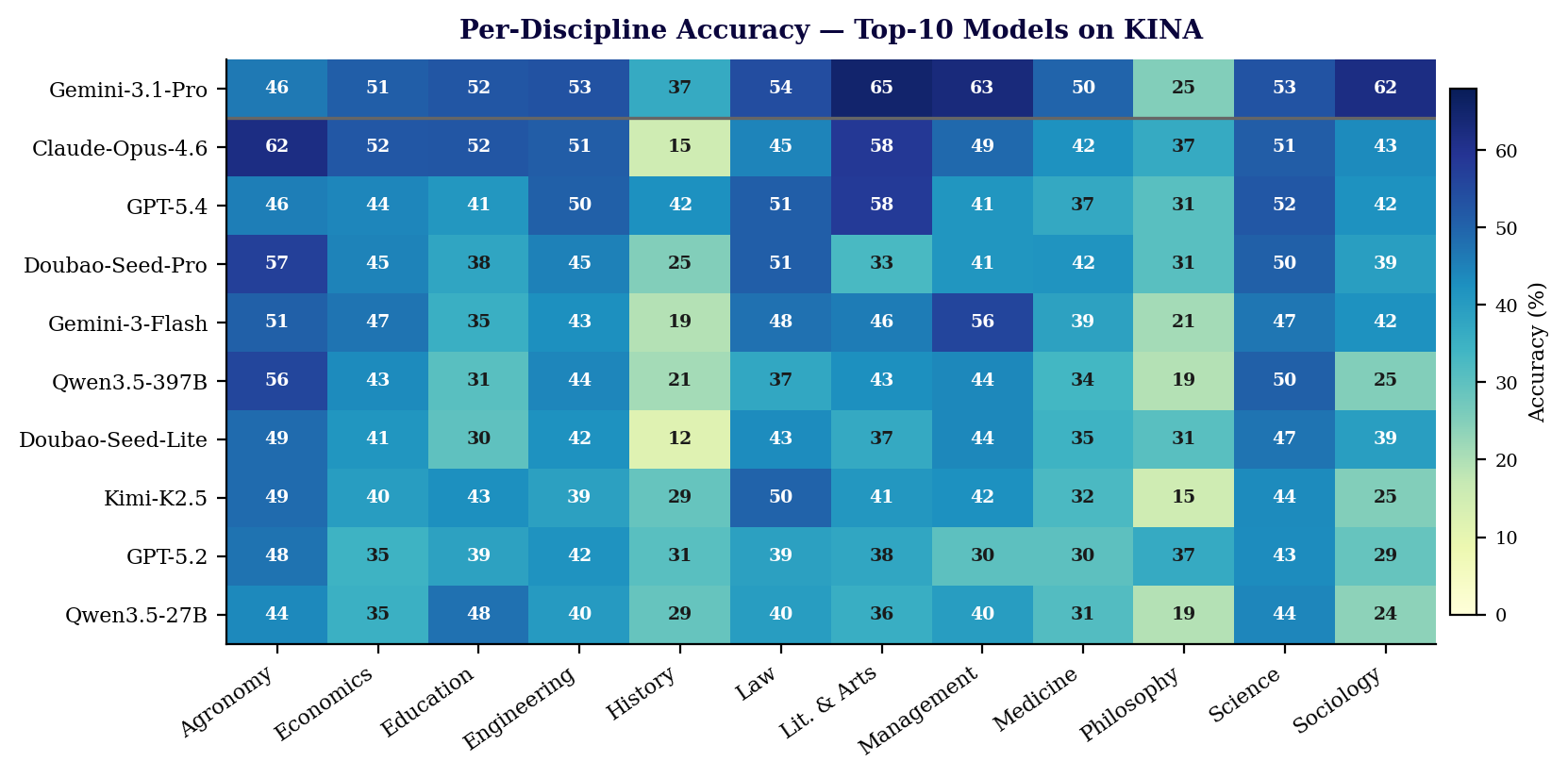
We evaluated 37 frontier models on KINA. Key findings include:
- Significant room for improvement remains in domain-specific knowledge, even for top models.
- Closed-source flagship models still maintain a leading position on knowledge-intensive tasks.
- Web search tools exhibit a non-monotonic, U-shaped efficacy: both weaker and stronger models benefit substantially, while mid-tier models benefit less. The strongest model (Gemini-3.1-Pro-Preview) recorded the largest absolute gain at +5.17%.
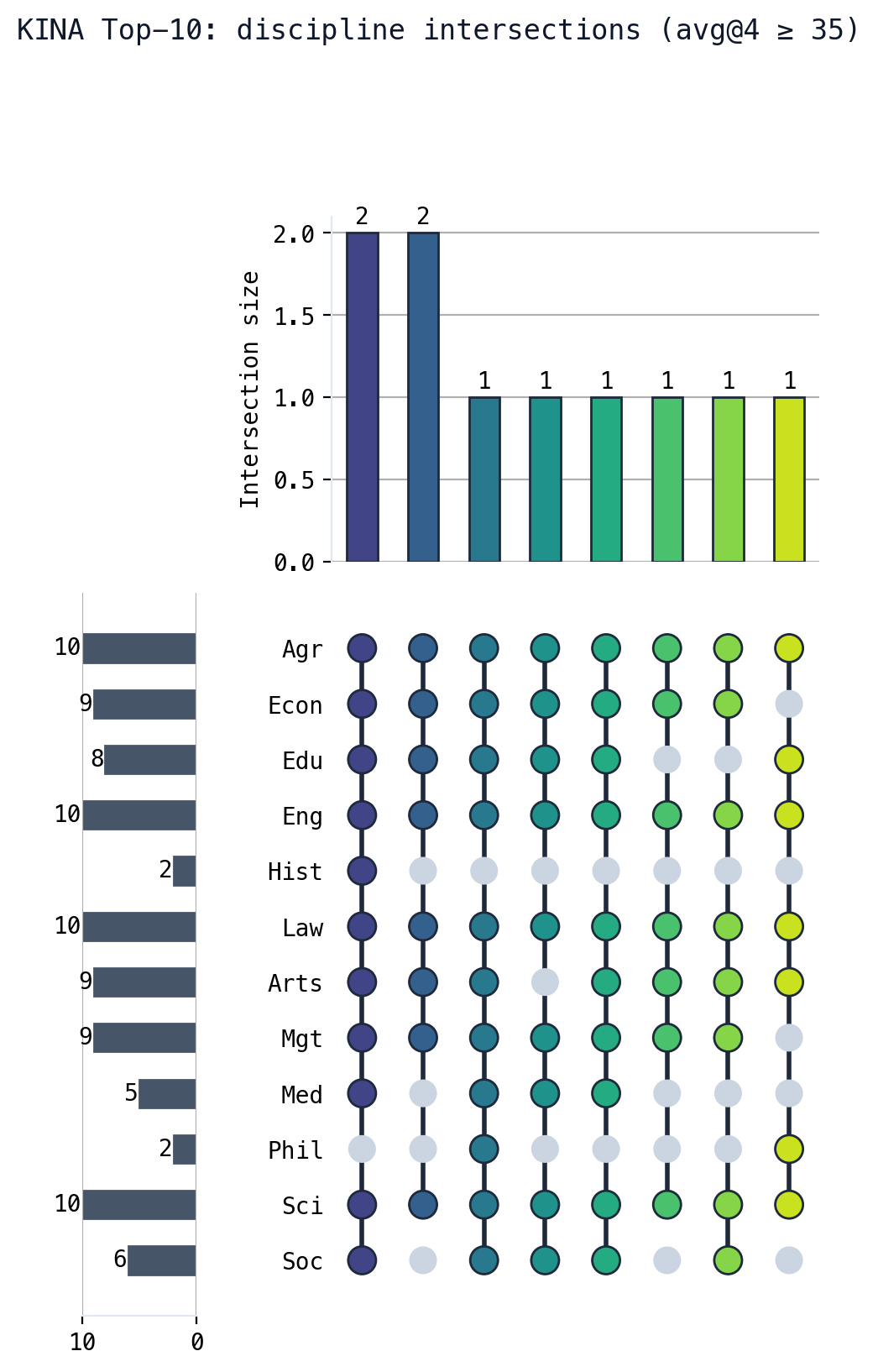
- The top-10 models show more pronounced performance differences in humanities and social sciences than in hard sciences.
KINA is designed to be continuously updated. The benchmark, annotation guidelines, and evaluation framework are released publicly alongside the dataset.