Persona Collapse
Why many “different” AI personas end up sounding strangely the same
This page is based on our paper, The Chameleon’s Limit: Investigating Persona Collapse and Homogenization in Large Language Models. The project studies a simple but important question: if we give a language model a richly specified persona, does it actually behave like a distinct individual, or does it quietly compress many different people into a few repeated behavioral types?
In simple terms, the paper argues that current LLMs are much better at looking persona-aware than at sustaining real population diversity. A model may sound convincing when judged one persona at a time, but when you step back and look at hundreds or thousands of simulated people together, many of those “different” agents collapse into a much smaller set of stereotyped response patterns.
We tested this at population scale. After filtering for consistency, the study evaluated 1,144 personas built from 26 persona dimensions such as age, gender, country, social class, politics, hobbies, and personality traits. We then measured behavior across three settings:
- Personality simulation using the BFI-44 inventory.
- Moral reasoning using 131 ethical scenarios.
- Self-introductions in free-form text.
For personality, we also compared model populations against 2,058 real human responses, which gives the paper a concrete human baseline rather than only model-vs-model comparisons.
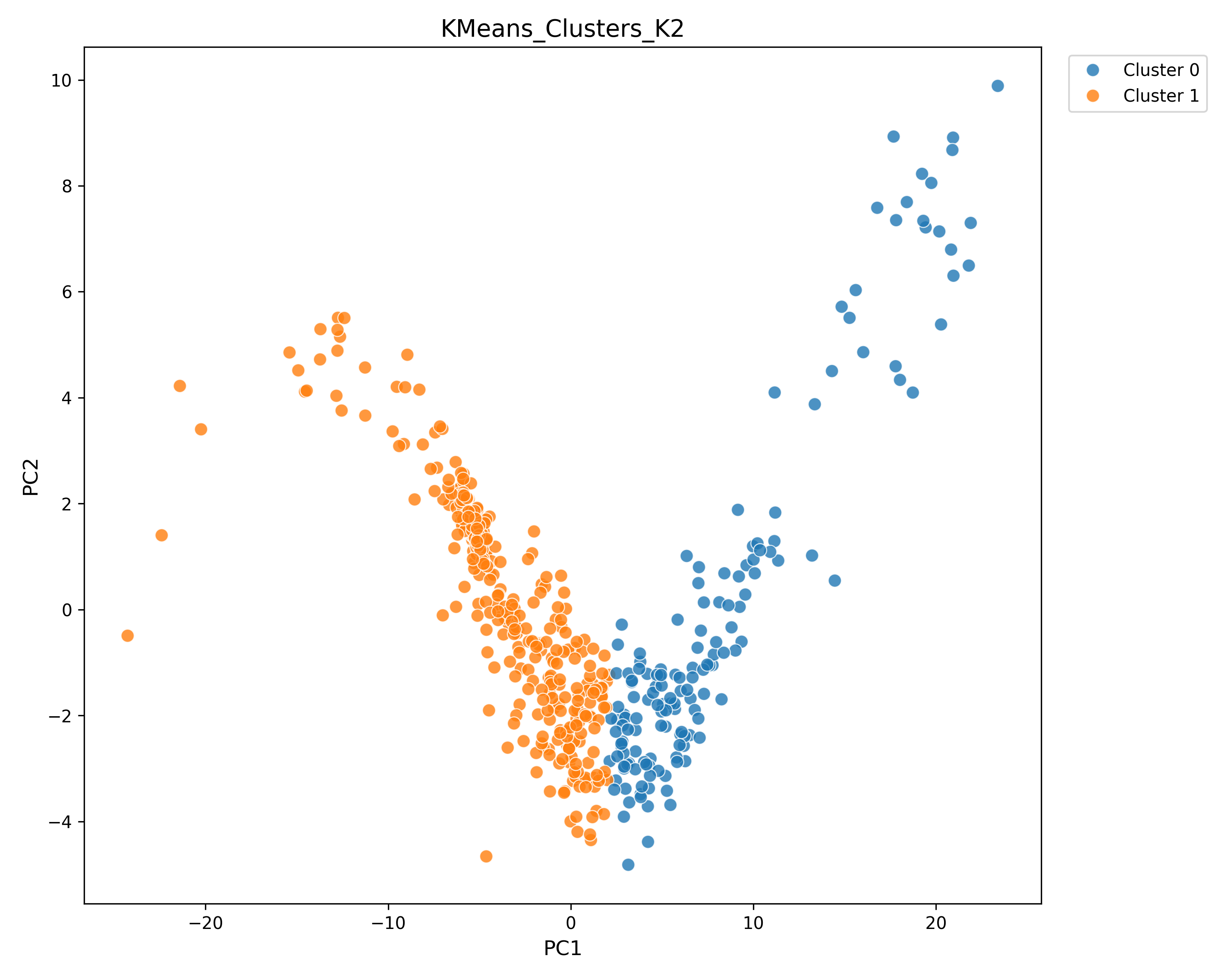
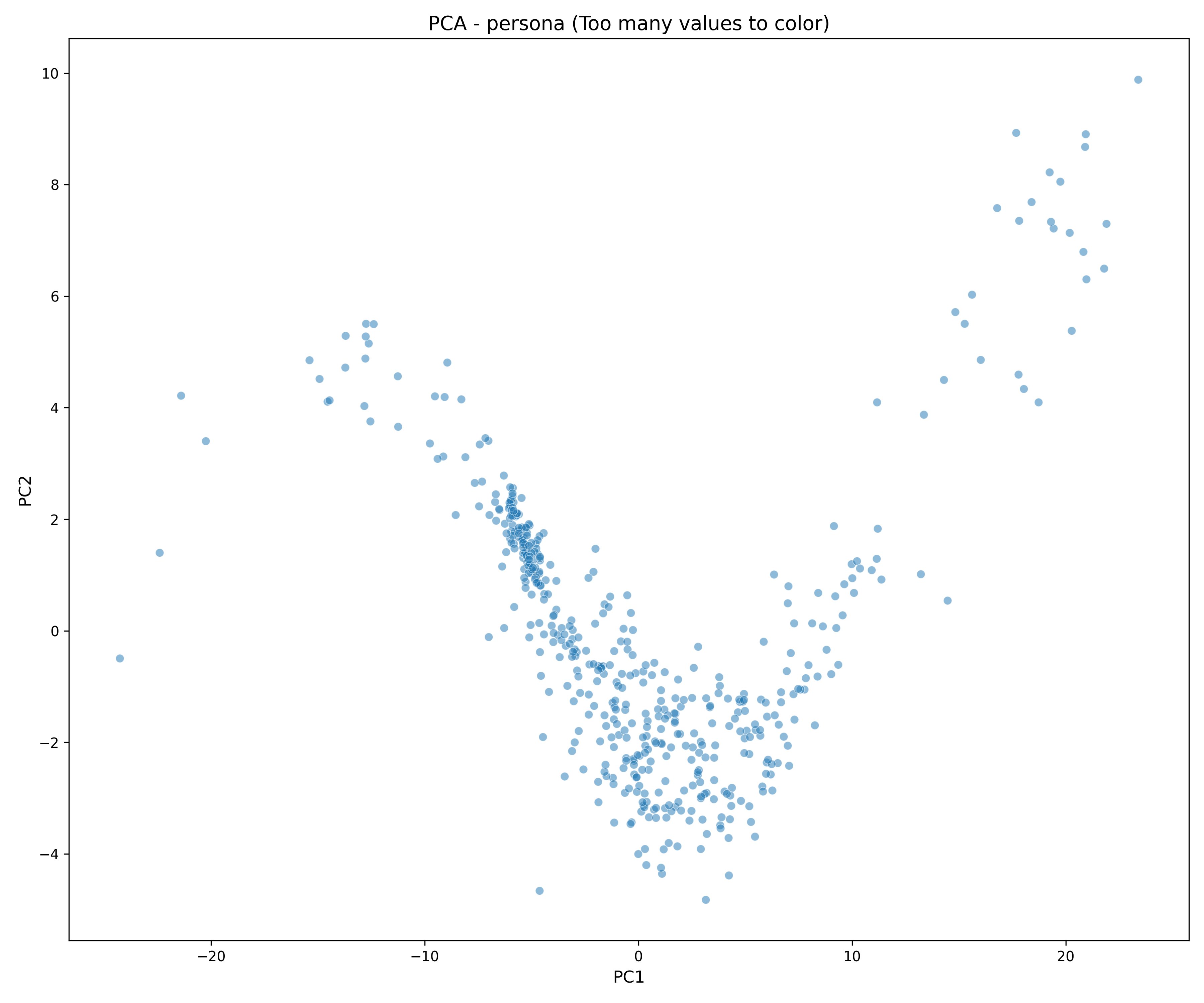
The visual intuition is the heart of the paper. Human populations tend to spread across behavioral space in a messy, diffuse way. But many model-generated populations form narrow shapes or a handful of clusters. That is what we call persona collapse: the persona prompt looks rich on paper, but the behavioral space the model actually occupies is much smaller and more repetitive.
The paper introduces three diagnostics to measure this in plain geometric terms:
- Coverage: how much of the human behavioral space the model reaches at all.
- Uniformity: whether the simulated population is spread out naturally, rather than bunching into a few dense pockets.
- Complexity: whether the variation is truly high-dimensional, or whether it only moves along a few hidden axes.
These three metrics matter because a model can look diverse in one shallow way while still failing in a deeper one. For example, a system might cover a lot of space but only along a thin line, or it might produce many outputs that still boil down to just a few stereotyped clusters.
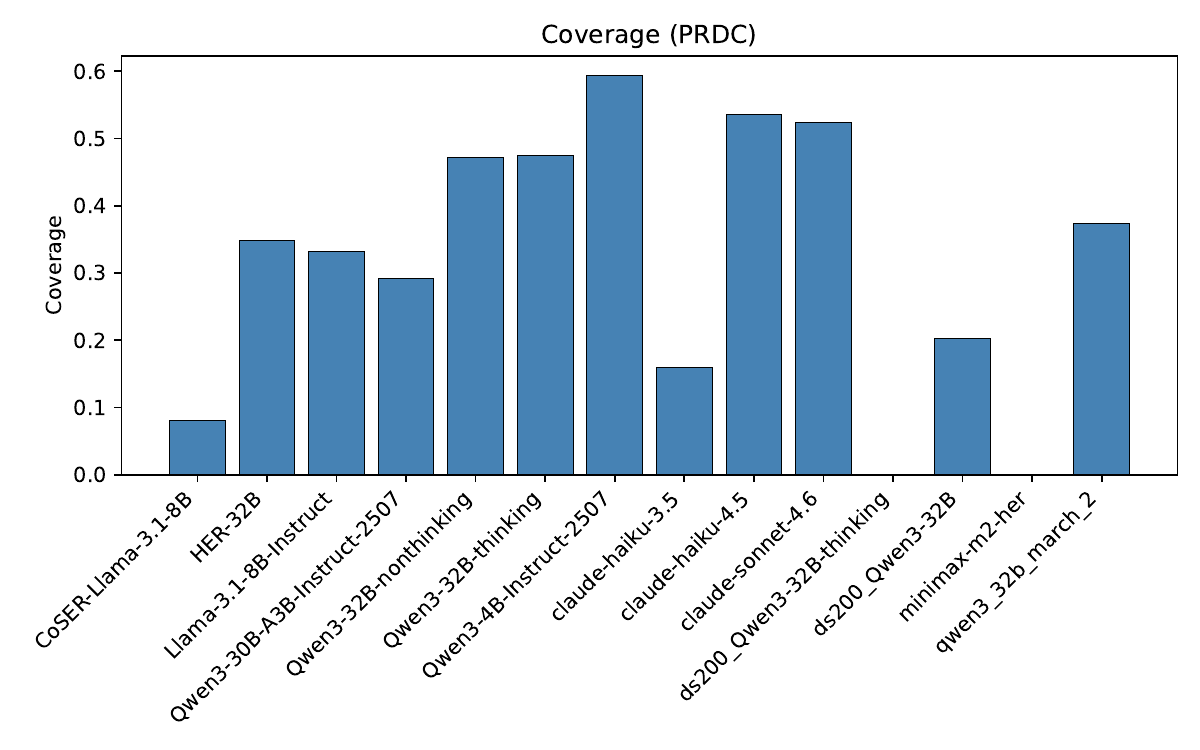
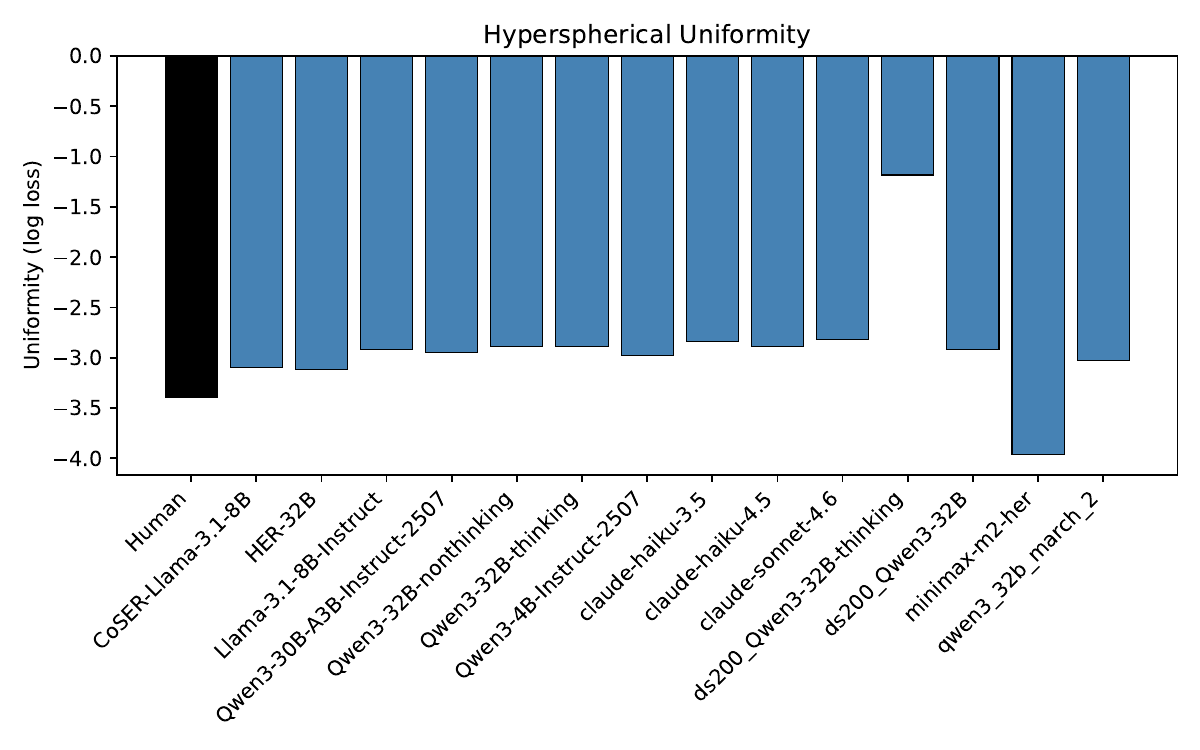
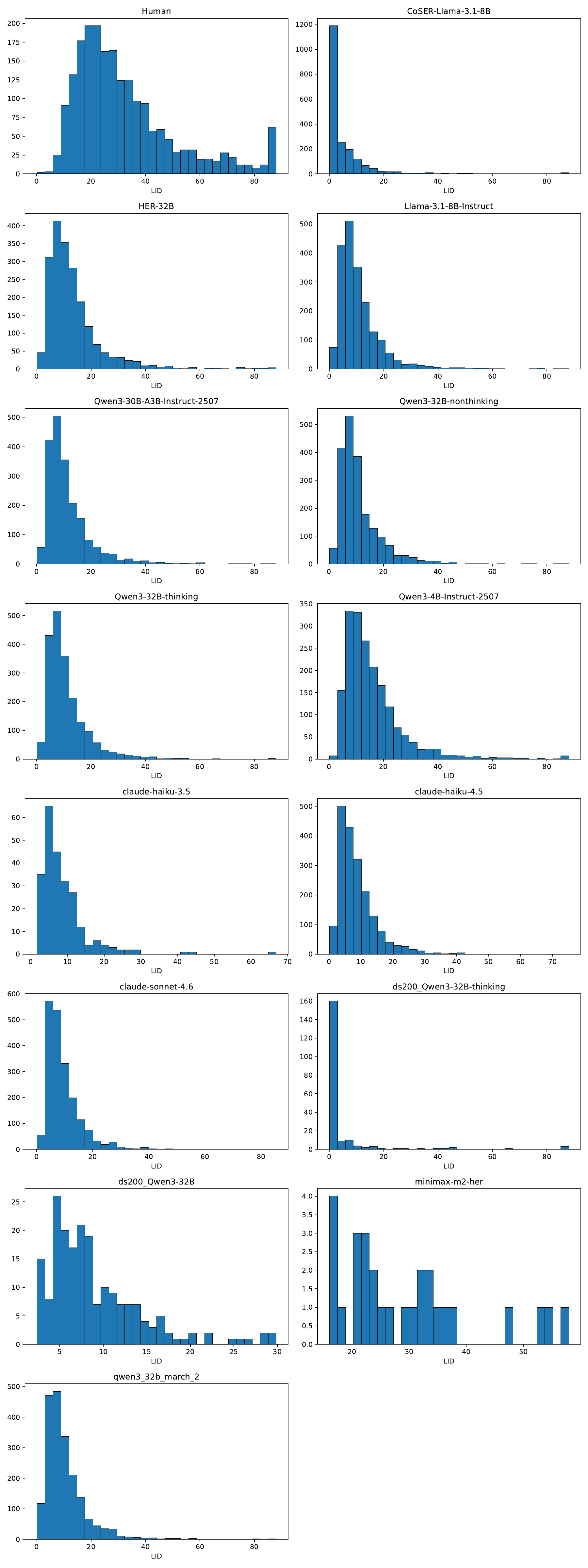
The main finding is that all tested models collapse somewhere, and often quite badly. No model simultaneously matches the human reference on both broad coverage and high complexity. Some models reach a fair amount of the human space, but in a flattened way. Others generate rich-looking variation that is poorly aligned with actual human structure. So the problem is not just “too little diversity.” It is also the wrong kind of diversity.
One of the most interesting results is that high persona fidelity can actually make the population worse. The paper shows that models which score best on per-persona fidelity often produce the most polarized, caricatured populations when evaluated as a whole. In other words, if you optimize too hard for “make this persona obvious,” the model may lean on coarse stereotypes instead of preserving fine-grained individuality.
Another important result is that collapse is domain-dependent. A model can be highly collapsed in personality simulation and much more diverse in moral reasoning, or the other way around. That means there is no single number that tells you whether a model is “good at personas.” You have to ask: good at what kind of persona behavior, in what domain, and under what evaluation lens?
The paper also goes beyond aggregate geometry and asks what information the models are actually keeping. At the item level, the answer is often disappointing: variation frequently tracks coarse demographic stereotypes more than the full persona specification. Instead of preserving the interaction of 26 attributes, models tend to latch onto a smaller subset of salient categories and ignore the rest.
This matters because persona simulation is increasingly used in synthetic surveys, agent-based social simulation, user testing, and AI products that claim to represent many kinds of people. If a system says it is simulating a thousand different individuals but really produces a few repeated templates, then the diversity is more cosmetic than real.
What I like about this project is that it shifts the question from “Did the model imitate this one persona well?” to “What kind of population does the model create when scaled up?” That population-level view makes collapse visible. It is a reminder that believable single examples are not enough; if we want AI systems to stand in for people, we also need them to preserve the structure of human variation rather than flatten it.