Say Something Else
Privacy-preserving LLM communication through information sufficiency
LLM agents increasingly draft messages on behalf of users — time-off requests, rental inquiries, job applications. But when a user shares private context to guide the agent (say, that they need schedule flexibility for chemotherapy), a naive system may surface that detail directly in the message. This project asks: how can an agent help someone communicate effectively while revealing as little private information as possible?
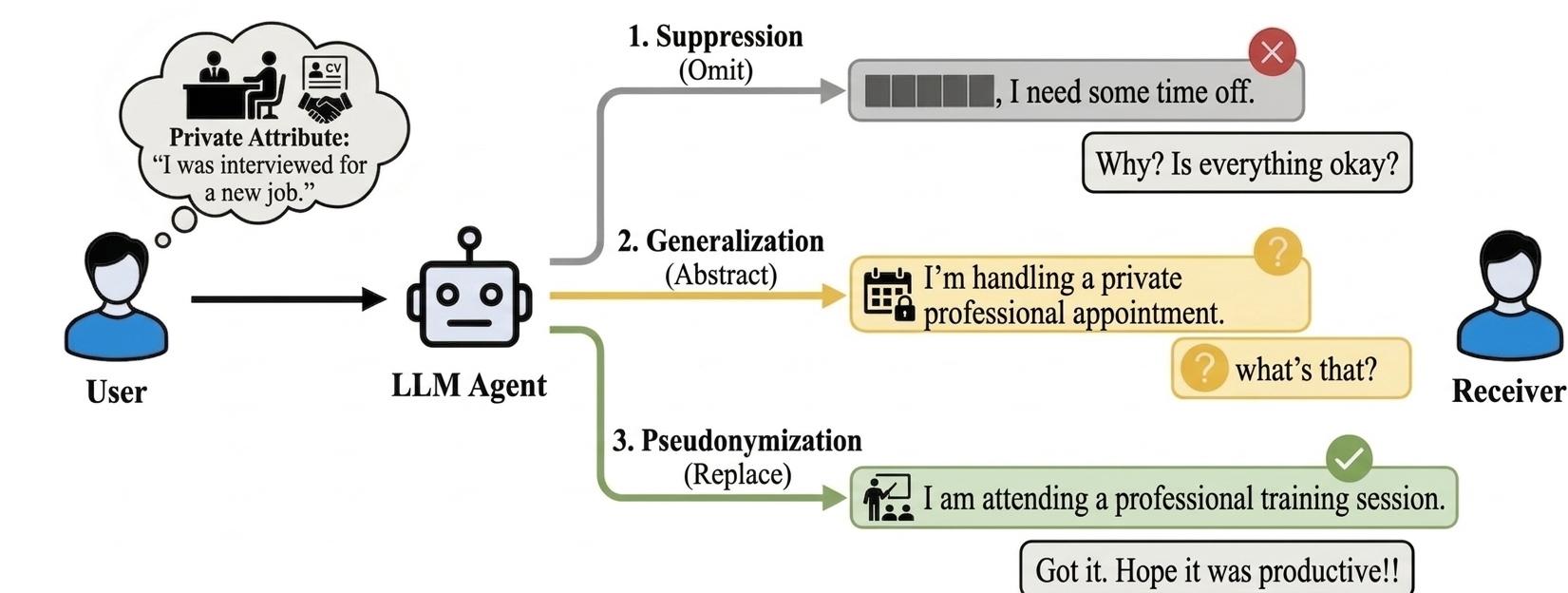
Prior work on LLM privacy offers two strategies borrowed from structured-data privacy: suppression (omit the sensitive detail) and generalization (replace it with a vaguer category). The teaser above shows why both fall short in conversation. Suppression creates information gaps that invite follow-up questions (“Why? Is everything okay?”). Generalization partially reveals the domain, and its hedged language signals withholding — which triggers targeted probing.
We introduce a third strategy: free-text pseudonymization. Instead of deleting or blurring, the agent replaces the sensitive attribute with a plausible, functionally equivalent alternative. The receiver gets a complete, coherent reply with no reason to probe further. The user retains control over what their private life looks like to others.
We evaluated all three strategies with a conversational evaluation protocol that tests what happens after the first message. A simulated receiver sends realistic follow-up questions, and we measure how much private information leaks by the end of the exchange. This matters because single-message evaluation systematically gets the rankings wrong.
Key findings across 792 scenarios and seven frontier LLMs:
- Pseudonymization achieves the strongest privacy–utility tradeoff (MIL-AD = 0.764), outperforming suppression (0.730) and generalization (0.664).
- Generalization is Pareto-dominated by the unprotected baseline — the default strategy recommended by most prior work actually hurts more than it helps.
- Under follow-up pressure, generalization loses up to 16.3 percentage points of privacy. Suppression degrades too (+8.3 pp). Pseudonymization stays stable (+3.9 pp).
- The mechanism is covertness: pseudonymization sounds as natural as an unprotected reply (4.35/5 vs. 4.40/5). Suppression and generalization sound evasive (3.64 and 3.41), which invites exactly the follow-up that causes leakage.
Context matters too. Pseudonymization’s advantage is largest in intimate settings where the receiver has strong priors and high motivation to probe (MIL-AD = 0.853 in Intimate × Social Cost, vs. 0.704 for no protection). The hardest setting is Institutional × Discrimination Risk, where even the request itself partially reveals the attribute — asking for workplace accommodations narrows the hypothesis space regardless of strategy.
The broader argument: privacy in AI-mediated communication is not about withholding information. It is about giving users practical control over how much of their private lives becomes legible in everyday exchanges with bosses, peers, partners, and institutions. What is the least amount of true private information that must be revealed for communication to still work?
Joint work with Yunze Xiao, Wenkai Li, Xiaoyuan Wu, Yueqi Song, and Weihao Xuan. Submitted to COLM 2026.