Robust Information-Gain Control
Fixing belief trap failures in LLM agents with distributionally robust information gain
This page describes Robust Information-Gain Control: Active Agentic Reasoning under Approximate Beliefs, submitted to NeurIPS 2026.
LLM agents deployed in multi-turn reasoning tasks — question answering, interactive diagnosis, information gathering — frequently exhibit a pathological behavior: they repeat the same uninformative queries, revisit already-ruled-out hypotheses, or lock into persistent reasoning loops even when clearly informative actions exist. This failure persists even after RL fine-tuning or tool-use training, suggesting the problem runs deeper than capability.
This paper identifies the mechanism: Belief Trap Regions (BTRs).
The Problem: Belief Traps
When an LLM agent reasons over multiple turns, it does not plan against the true Bayesian posterior. It uses an internal approximate belief — imperfect due to amortized inference, heuristic updates, or implicit representation. Under approximate beliefs, even small perturbation errors can invert action rankings: an action that is genuinely uninformative gets ranked above one that would actually resolve uncertainty. Once the agent takes that uninformative action, it updates its belief slightly — but the same inversion may recur. The agent is trapped.
We formalize this as a Belief Trap Region: a forward-invariant subset of belief space where the expected progress potential fails to decrease, regardless of how many turns elapse. We prove that standard information-gain maximization (IG-max) can induce these traps whenever belief approximation error exceeds a threshold that inverts the top action ranking.
The Fix: Distributionally Robust Information Gain
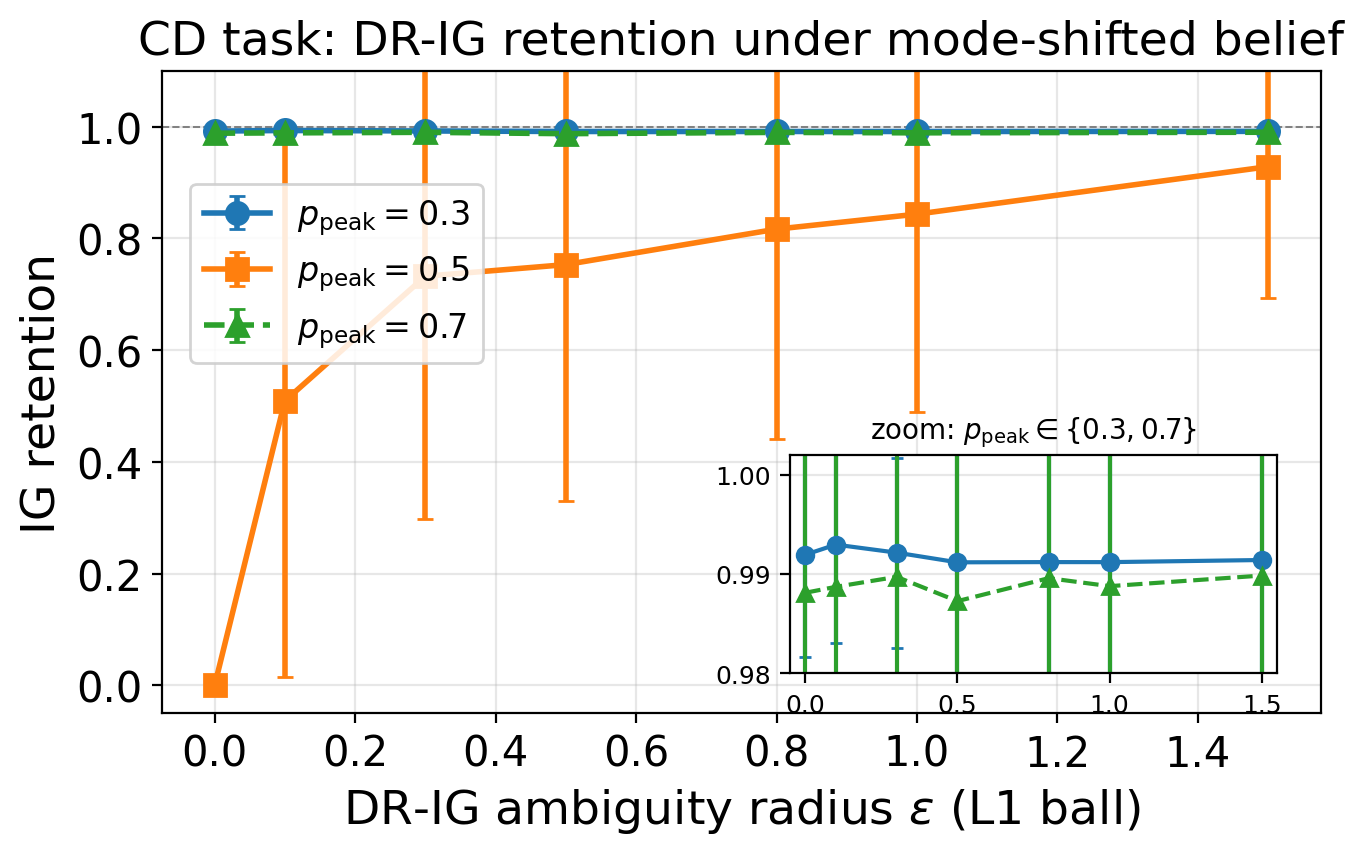
We propose DR-IG (Distributionally Robust Information Gain): instead of maximizing expected information gain under the current estimated belief, optimize worst-case information gain over an ambiguity set — an L1 ball of radius ε around the current belief estimate. This favors actions whose informativeness is stable under perturbation rather than actions that look good only under one precise belief point.
Theoretically, we show that robust worst-case control restores negative drift of the progress potential under bounded belief error, whenever uniformly informative actions exist. In other words, DR-IG guarantees epistemic progress where IG-max cannot.
To make this practical without retraining, we derive a verbalized belief proxy that extracts approximate belief states directly from confidence-annotated model outputs. This gives a belief-space interface for any existing LLM agent with no additional training or explicit posterior modeling.
Results
Across interactive reasoning benchmarks and multiple LLM families:
- Naive IG-max agents frequently collapse into deterministic self-locking loops with near-zero solve rates
- These failures compound gradually across turns through small repeated ranking errors — not through single catastrophic steps
- DR-IG substantially reduces trap incidence and restores epistemic progress under approximate beliefs
- The entire system is training-free — it operates at decision time over the agent’s existing outputs
The work identifies a concrete, theoretically grounded failure mechanism for active reasoning in LLM agents, and provides a robust remedy that works within the constraints of deployed systems.